



近日,一项发表于《自然》(Nature)期刊的突破性研究显示,加州大学戴维斯分校的研究人员开发出一种全新的脑机接口(Brain-Computer Interface,简称BCI),可以将人类大脑的神经活动实时转化为语音,帮助因神经系统疾病而失语的患者“重新开口说话”。
这项技术在一位患有肌萎缩侧索硬化症(ALS)的试验参与者身上进行了验证。他通过该系统能够在与家人交流时实现实时语音输出,不仅可以正常“说话”,还能够自主调节语调、甚至尝试哼唱简短旋律。
“过去我们的脑机接口技术是把大脑信号翻译成文字,相当于‘发短信’。尽管相比传统辅助工具已是巨大进步,但交流还是存在延迟。”论文的通讯作者、加州大学戴维斯分校神经外科助理教授Sergey Stavisky表示,“而这项新技术则更像是一通‘语音电话’,实现了几乎即时的语音合成。”
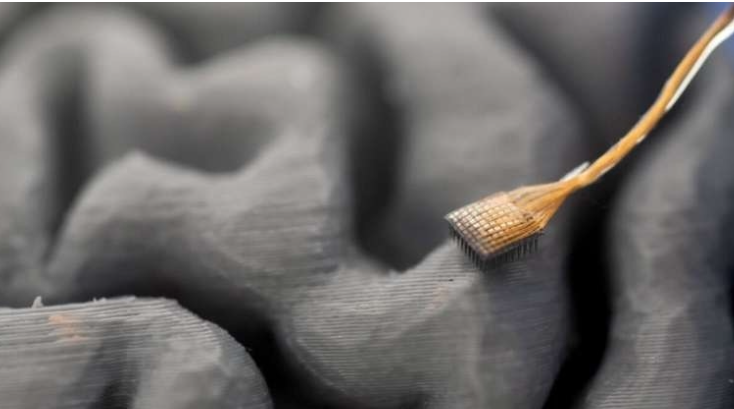
声音的“数字化声道”
研究人员为试验参与者植入了四块微电极阵列,位置在控制语言表达的大脑区域。这些电极实时记录大脑神经元的活动,并将信号发送至计算机进行解码和语音合成。
“实现实时语音合成的一大难点在于,系统需要精准判断患者在‘何时’以及‘如何’尝试说话。” 论文第一作者、UC Davis神经假体实验室科学家Maitreyee Wairagkar解释道,“我们的算法能够将特定时刻的神经信号对应到特定语音,从而捕捉语言节奏和语调变化。”
该系统的响应时间仅为1/40秒,与人类正常说话时听见自己声音的时间延迟几乎一致。这种极低延迟意味着患者可以主动参与对话、打断别人,或者用语音强调某些内容,从而大大提升了交流的自然性和流畅度。

不只是说话,还能唱歌
这名参与者还能通过BCI系统说出系统未曾预设的新词语,并在说话时进行情感表达,例如升调以表达疑问、强调关键词等。他还尝试了哼唱简单旋律,表现出初步的音高控制能力。
实验中,BCI合成语音的识别度也令人鼓舞。听众能够正确识别约60%的合成词汇,而在不使用BCI的情况下,这一识别率仅为4%。
算法与人工智能是关键
该系统的语音合成功能依赖于人工智能算法的深度学习能力。训练算法时,研究人员要求参与者默读屏幕上显示的句子,同时记录其大脑神经元的放电模式,并将这些模式与目标语音进行匹配。这使得系统逐渐“学会”如何从神经信号中重建语音。

迈向临床应用的新希望
“声音是我们身份的一部分。对神经疾病患者来说,失语是一种毁灭性的打击。” 加州大学戴维斯分校神经外科助理教授、试验主刀医师David Brandman表示,“这项研究让我们看到失语者通过BCI重新‘开口说话’的可能,这种技术有潜力彻底改变瘫痪患者的生活。”
目前,该项技术仍处于临床研究早期阶段。研究仅在一位ALS患者身上完成,下一步,研究团队计划扩大参与者范围,包括因中风等其他原因导致失语的患者,以验证技术的普适性和稳定性。
参考文献:Maitreyee Wairagkar, An instantaneous voice-synthesis neuroprosthesis, Nature (2025). DOI: 10.1038/s41586-025-09127-3. www.nature.com/articles/s41586-025-09127-3
